A Minimum Complete Tutorial of Linux ext4 File System
Introduction
I will describe Linux ext4 file system as simple and as comprehensive as possible with examples.
Disclaimer: I am not an expert on ext4. Although I aim to make this article comprehensive enough to understand how ext4 works, I have omitted many features, so it is not a full description.
I named this post a “Minimum Complete Tutorial”, because I will try to keep the content minimal by omitting the optional parts and extra features while completely describing everything in a fully functional ext4 file system. ext4 is not very simple, you probably need a few hours to go over everything written in this post.
I did not execute the examples in this Tutorial in order, and because the file system is very dynamic, there can be inconsistencies between sections or if you try to do it yourself and compare your results to the one I show in this post. However, this does not affect anything in terms of understanding how it works.
Resources
While writing this post, I have used the Ext4 Disk Layout documentation, the source of ext4 file system (in Linux Kernel), the source of e2fsprogs package (includes debugfs and dumpe2fs) and the source of coreutils package (includes ls).
History
ext4 is the default Linux filesystem since 2010. It is the successor of ext3 which is the successor of ext2. ext means extended filesystem and if you wonder, yes, there is also ext (v1, without any number in the name) but it was used for a very short time (around 1992) and ext2 replaced it very quickly. ext3 is introduced around 2000 with journaling support.
Tutorial
Creating the ext4 file system
If you are using Linux, you are probably already using ext4 as your main file system. However, it is the best to have a play area, so I will create an ext4 file system on a USB memory stick, attached to /dev/sda.
First, I have created a GUID Partition Table (GPT) with a single Linux partition on it. If you are not familiar with GPT and Logical Block Addressing (LBA), I recommend you to read my post about GPT first: A Quick Tour of GUID Partition Table (GPT).
Warning ! Be very very careful using fdisk and mkfs, and make sure the device you are writing to is the one you do not have any important data.
Here is the partition table:
$ sudo fdisk /dev/sda
Welcome to fdisk (util-linux 2.27.1).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Command (m for help): p
Disk /dev/sda: 14.9 GiB, 16008609792 bytes, 31266816 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: gpt
Disk identifier: 68B7F722-7E83-47F7-BCCC-2C7591B95E0C
Device Start End Sectors Size Type
/dev/sda1 2048 31266782 31264735 14.9G Linux filesystem
The logical block size is 512B . The partition starts at Logical Block 2048 and ends at Logical Block 31266782.
Lets create the file system.
$ sudo mkfs -t ext4 /dev/sda1
mke2fs 1.42.13 (17-May-2015)
Creating filesystem with 3908091 4k blocks and 977280 inodes
Filesystem UUID: 5ae73877-4510-419e-b15a-44ac2a2df7c6
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208
Allocating group tables: done
Writing inode tables: done
Creating journal (32768 blocks): done
Writing superblocks and filesystem accounting information: done
mkfs, make file system, creates a file system whose type is specified with -t, here ext4. mkfs is actually a wrapper and actually executes mkfs.<fs> so here mkfs.ext4 does the job.
The information we see here are:
- A filesystem is created consisting of 3908091 blocks.
- Block size of 4096B is the automatically selected value, we can create with another block size also. This block size is not the logical block size (of LBA), it is the file system block size, and ~4M blocks mentioned above are the file system blocks not Logical Blocks.
- There are 977280 inodes. We will see what an inode is.
- Filesystem UUID is the partition UUID in GPT.
- There is something called Superblock with 9 backups.
- There are things called group tables, inode tables and journal.
- There is something called accounting information. I have actually looked up to source code of mkfs for this, and it actually only writes out the information for the file system and closes the structures. So it is not something to be specifically mentioned in this post.
I will explain all of these and related concepts in this post.
Superblock
We start with the Superblock, as its location is fixed and it contains the basic file system information. We can dump its contents with dumpe2fs and -h option prints only the Superblock.
$ sudo dumpe2fs -h /dev/sda1
Filesystem volume name: <none>
Last mounted on: <not available>
Filesystem UUID: 8eefa5bb-858c-4bd0-b80d-1aebc23de317
Filesystem magic number: 0xEF53
Filesystem revision #: 1 (dynamic)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype extent flex_bg sparse_super large_file huge_file uninit_bg dir_nlink extra_isize
Filesystem flags: signed_directory_hash
Default mount options: user_xattr acl
Filesystem state: clean
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 977280
Block count: 3908091
Reserved block count: 195404
Free blocks: 3804437
Free inodes: 977269
First block: 0
Block size: 4096
Fragment size: 4096
Reserved GDT blocks: 954
Blocks per group: 32768
Fragments per group: 32768
Inodes per group: 8144
Inode blocks per group: 509
Flex block group size: 16
Filesystem created: Wed Aug 23 11:20:00 2017
Last mount time: n/a
Last write time: Wed Aug 23 11:20:00 2017
Mount count: 0
Maximum mount count: -1
Last checked: Wed Aug 23 11:20:00 2017
Check interval: 0 (<none>)
Lifetime writes: 132 MB
Reserved blocks uid: 0 (user root)
Reserved blocks gid: 0 (group root)
First inode: 11
Inode size: 256
Required extra isize: 28
Desired extra isize: 28
Journal inode: 8
Default directory hash: half_md4
Directory Hash Seed: 648ce1ac-dd8d-40a6-ac6f-238b2e7d97d1
Journal backup: inode blocks
Journal features: (none)
Journal size: 128M
Journal length: 32768
Journal sequence: 0x00000001
Journal start: 0
There are plenty of information here and I will explain most of it.
The most basic storage layout concept of ext4 is Block. ext4 allocates storage in a series of blocks, just like LBA. However the ext4 Block size can be different. Block size in Superblock is 4096B = 4KB. There are Block count, 3908091, number of blocks in this filesystem.
The second basic storage layout concept of ext4 is Block Group. Blocks per group number of contiguous Blocks are organized into Block Groups, and in our file system it is 32768 = 32K.
Since we have 3908091 blocks, dividing this to 32K:
3908091 / 32768 = 119, and since it is not a multiple of 32K,
there is one more with less than 32K blocks.
So we have 120 Block Groups each containing 32K Blocks (except the last one), and each block is 4KB, and since each logical block is 512B, this means each block contains 8 logical blocks. This is the basic organization of ext4 on the storage, and see the figure below for a visual summary.

1 Block Group = 32768 File System Blocks = 32768 * 8 Logical (Storage) Blocks
Each block group contains:
- Superblock, contains information about the file system. It is one block and the first block.
- Group Descriptors (or Group Descriptors Table or Block Group Descriptors or Block Group Descriptors Table), contains the location of where the Data Block Bitmap, inode Bitmap and inode Table are in a Block Group. So there are as many Group Descriptors as number of Block Groups. Depending on the number of Block Groups, it is one or more blocks. It always follows the Superblock.
- Reserved Group Descriptor Table (GDT) Blocks. When you first create the file system, these blocks are reserved for future expansion of the file system, since ext4 file system can be enlarged later. Future expansion means more Blocks and Block Groups, so there will be a need for more Group Descriptors. It is zero or more blocks and always follows the Group Descriptors. resize_inode filesystem feature indicates there are reserved blocks for filesystem expansion.
- Data Block Bitmap, indicates which data blocks are in use. It is one block. Its location is not fixed, it is indicated in the Group Descriptor.
- inode Bitmap, indicates which entries in inode table are in use. It is one block. Its location is not fixed, it is indicated in the Group Descriptor.
- inode Table, contains inodes (inode structures). Inode is basically a data structure for every file and directory. It is one or typically more blocks. Its location is not fixed, it is indicated in the Group Descriptor.
- Data blocks, keep the actual contents of the files. It is one or typically more blocks. It is basically all other blocks in a Block Group.
As expected, each bit in (Data Block and inode) Bitmap, indicates the usage of one data block or one entry in inode Table. Since a Bitmap is one block and one block is 4KB so 32Kbits, there can be maximum 32K blocks in a Block Group — which is already the case. Also, there can be a maximum of 32K inodes in a Block Group, but we have only 8144, Inodes per group, now.
Looking at the Superblock again:
- Reserved GDT blocks: 954, number of blocks reserved for future expansion of the filesystem.
- Inode blocks per group: 509, size of inode Table in each block group. This number is connected to two other numbers. Inode Size, 256B , and there are, Inodes per group, 8144 of them, so 256B * 8144 / 4096B = 509 blocks per group for inodes.
You may think now we know all about the layout of the ext4 file system, but we still do not. It is important we look into two Filesystem features (see Superblock), sparse_super and flex_bg which affects the layout.
Superblock Backups
Since the Superblock contains important information, and losing it results in a complete failure of the file system (you cannot read the filesystem if you do not know the parameters I mentioned above), it has backups (or in other words there are redundant copies of it) in every Block Group. However, this can be too much. In our example, which is a small file system, do we need 120 backups ? So sparse_super feature indicates the redundant copies of the Superblock are only kept in a few block groups, specifically with block group number 0 (which is the primary copy) and if block group number is a power of 3, 5 or 7.
Calculating this for our case, from block numbers 0 to 119 (inclusive), we expect the following block groups to contain redundant copies:
1 3 5 7 9 25 27 49 81
If we multiply each with 32768 (blocks per group), we can find the block numbers as shown in the mkfs output:
32768 98304 163840 229376 294912 819200 884736 1605632 2654208
sparse_super also affects the Group Descriptors . By default, Group Descriptors is present in every Block Groups like the Superblock. If sparse_super is present, it is only present in the Block Groups containing the redundant copies of the Superblock as calculated above. We can assume the Superblock and Group Descriptors stay always together.
Block Groups and Flex Block Groups
The other filesystem feature we will look is flex_bg which means Flexible Block Groups. This feature is added with ext4. Flexible Block Groups are basically another level of organization over the Block Group, where a Flexible Block Group contains a group of contiguous Block Groups, basically aggregating the data block bitmaps, inode bitmaps and inode tables of all block groups in a flexible block group into the first block group.
If we look at the Superblock, Flex block group size is 16. So 16 contiguous Block Groups are packed into a Flex group, and the first Block Group in each Flex Group will contain the data block bitmaps, inode bitmaps and inode tables of all Block Groups (0..15).
We have:
119 / 16 = 7, and again 119 is not a multiple of 16,
so there is one more with less than 16 Block Groups.
8 Flexible Block Groups. The last Flexible Block Group contains only 8 Block Groups (112, 113, 114, 115, 116, 117, 118, 119).
Note: There is also a meta_bg file system feature which we do not have here. Meta Block Groups can organize Block Groups differently.
In order to understand Block Group contents, I think it is easier to think there are 3 types of Block Groups (Please be aware this is how I describe, it is not an official categorization):
- Type 1a (Block Group 0, if Block Size = 1024B): Block 0 is marked as used and not used (so first 1024B are not used). Block 1 contains the primary Superblock, then many blocks of Group Descriptors and Reserved GDT Blocks follows; then same as Type 3.
- Type 1b (Block Group 0, if Block Size > 1024B): First 1024B of Block 0 is padding and not used. Block 0 contains primary Superblock (after offset 1024), then many blocks of Group Descriptors and Reserved GDT Blocks follows; then same as Type 3.
- Type 2: Block Groups containing backup copies of Superblock and Group Descriptors. Block 0 is Superblock, then many blocks of Group Descriptors and Reserved GDT Blocks follows; then same as Type 3.
- Type 3: Block Groups not containing backup copies of Superblock and Group Descriptors. They may contain Data Bitmap(s), inode Bitmap(s), inode Table(s) and Data Blocks. The location of Bitmaps and inode Table is indicated in the Group Descriptor, so the order may not be like this.
The first 1024 bytes in Block 0 can be used for boot code, that is why it is not used in ext4.
The First block value, 0, in Superblock is used for this purpose and when Block Size is 1024. If you create the ext4 file system with:
$ mkfs -t ext4 -b 1024 /dev/sda
it uses 1K blocks. If you dump the Superblock of it and look at the First Block:
$ sudo dumpe2fs -h /dev/sda1 | grep "First block"
First block: 1
we can see the Block 0 is completely discarded.
As far as I understand, there is no other use of this value, it is either 1 or most of the time it is 0.
In our example:
- number of Type 1b Block Groups: 1 (only Block Group 0)
- number of Type 2 Block Groups: 9 (ones containing the Superblock backups
- number of Type 3 Block Groups: 110 (all others)
When we have Flexible Block Groups, we can have sub groups of each types since only the the first block of Flex Group contains the Bitmaps and inode Table. So I will name them like Type 2-head and Type 2-rest. Type 1 is always head since it is always Block Group 0.
Also, Type 2-head Block Group is impossible. Because the number of a Block Group with a backup should be a power of 3, 5 or 7 (so an odd number) and it has to be divisible by the number of Block Groups in a Flexible Block Group, which in turn can only be a power of 2 (so an even number), and a number cannot be both odd and even, so there is no such number and Type 2-head is not possible.
Now we know all about the layout of Block Groups and Blocks of our ext4 file system. We can actually dump information about all of the Block Groups with dumpe2fs.
$ sudo dumpe2fs /dev/sda1 > dump
The dump file is long since it contains information for every Block Group (120 of them). I will show you only a few, one from each type.
First Block Group (Block Group 0):
Group 0: (Blocks 0-32767) [ITABLE_ZEROED]
Checksum 0x9a88, unused inodes 8131
Primary superblock at 0, Group descriptors at 1-1
Reserved GDT blocks at 2-955
Block bitmap at 956 (+956), Inode bitmap at 972 (+972)
Inode table at 988-1496 (+988)
23630 free blocks, 8133 free inodes, 2 directories, 8133 unused inodes
Free blocks: 9138-32767
Free inodes: 12-8144
As we know now:
- It contains Blocks 0–32767, since each Block Group contains 32K blocks.
- It contains Superblock at Block 0.
- It contains Group Descriptors at Block 1 (and only 1).
- It has Reserved GDT Blocks, Blocks 2 to 955.
- It has the Data Block Bitmap at Block 956, Inode Bitmap at 972. You will see soon why Inode Bitmap is not at 957.
- It has the inode table at Block 988 to 1496. There are 1496–988+1=509 Blocks as indicated in Superblock. +1 is because 1496 is inclusive.
You can also find these indices directly without using dumpe2fs.
The Block Group Descriptors starts from the second block, so dd bs=4096 skip=1. First three 32-bit numbers are Data Block Bitmap, inode Bitmap and inode Table locations.
$ sudo dd if=/dev/sda1 bs=4096 skip=1 count=1 status=none | hexdump -n 12 -s 0 -e '"%d %d %d\n"'
956 972 988
Block Group 0 is Type 1b (head) in my categorization.
Second Block Group, Block Group 1:
Group 1: (Blocks 32768-65535) [INODE_UNINIT, ITABLE_ZEROED]
Checksum 0x5017, unused inodes 8144
Backup superblock at 32768, Group descriptors at 32769-32769
Reserved GDT blocks at 32770-33723
Block bitmap at 957 (bg #0 + 957), Inode bitmap at 973 (bg #0 + 973)
Inode table at 1497-2005 (bg #0 + 1497)
31809 free blocks, 8144 free inodes, 0 directories, 8144 unused inodes
Free blocks: 33726-33791, 33793-65535
Free inodes: 8145-16288
- It has a backup copy of the Superblock, since 1 is a power of 3 1 = 3⁰ .
- Since it has the backup copy of the Superblock, it also has Group Descriptors and Reserved GDT blocks.
- It actually contains no Data Block, no inode Bitmaps and no inode Table. They are referenced to Block Group 0 (e.g. Data Block Bitmap of Block Group 1 is at bg #0 + 957) because Block Group 1 and 0 is in the same Flexible Block Group. Same is true for inode Bitmap and inode Table. This is the reason why the Data Block Bitmap and inode Bitmap is not consecutive in Block Group 0, former starts at 956, latter starts at 972. This is 16 Blocks because it contains the information from all other Block Groups (from 1 to 15) in the Flexible Block Group. Similarly for inode Table, which has a size of 509 blocks as indicated in the Superblock, from Block 988 to 9132, there are inode Tables of Block Groups 1 to 15.
It puzzled me and maybe you also wonder, in Block Group 0, why does the inode Table end at 9132 but free blocks start at 9138 ? Blocks 9132-9137 are actually data blocks and in use, so nothing strange is going on. If you repeat this example, you may get different output, since I was playing with the filesystem while writing the post.
So conceptually, it is not correct to say data blocks follow these metadata structures. Instead, it is correct to say all blocks are data blocks, but some are used for metadata. The ones used for metadata is also marked as used in Data Blocks Bitmap.
Block Group 1 is Type 2-rest in my categorization. It contains the backup, but it is not the first Block Group in Flexible Block Group.
Next, Block Group 2:
Group 2: (Blocks 65536-98303) [INODE_UNINIT, BLOCK_UNINIT, ITABLE_ZEROED]
Checksum 0xeabf, unused inodes 8144
Block bitmap at 958 (bg #0 + 958), Inode bitmap at 974 (bg #0 + 974)
Inode table at 2006-2514 (bg #0 + 2006)
32768 free blocks, 8144 free inodes, 0 directories, 8144 unused inodes
Free blocks: 65536-98303
Free inodes: 16289-24432
- It contains no backup Superblock, so no Group Descriptors and Reserved GDT blocks.
- Its Data Block Bitmap, inode Bitmap and inode Table is in Block Group 0, as same as Block Group 1.
Block Group 2 is Type 3-rest in my categorization. It has no backup, and it is not the first Block Group in Flexible Block Group.
If we look at Block Group 16, which is in the next Flexible Block Group:
Group 16: (Blocks 524288-557055) [INODE_UNINIT, ITABLE_ZEROED]
Checksum 0x8ab4, unused inodes 8144
Block bitmap at 524288 (+0), Inode bitmap at 524304 (+16)
Inode table at 524320-524828 (+32)
24592 free blocks, 8144 free inodes, 0 directories, 8144 unused inodes
Free blocks: 532464-557055
Free inodes: 130305-138448
- It contains no backup Superblock, so no Group Descriptors and Reserved GDT blocks.
- It has the Data Block Bitmaps, inode Bitmaps and inode Tables for all other Block Groups (16–31) in this Flexible Block Group.
Block Group 16 is Type 3-head in my categorization. It has no backup, but it is the first Block Group in the Flexible Block Group.
There are a few flags we see above. These are used to reduce the mkfs time by not initializing / zeroing some of the structures.
INODE_UNINIT: inode Bitmap is not zeroed, because it can be calculated on-the-fly (e.g. no inodes are used so all of them are free).
ITABLE_ZEROED: inode Bitmap is zeroed.
BLOCK_UNINIT: Data Block Bitmap is not zeroed. (e.g. no data stored so all of them are free).
This feature is set with filesystem feature uninit_bg, see Superblock.
See below for a visual summary. Each row is a Flexible Block Group, each cell is a Block Group. Remember the backup copies of the Superblock are in 1, 3, 5, 7, 9, 25, 27, 49 and 81 , and only the first cell (first Block Group in a Flexible Block Group) contains the Data Block and inode Bitmaps and inode Tables.
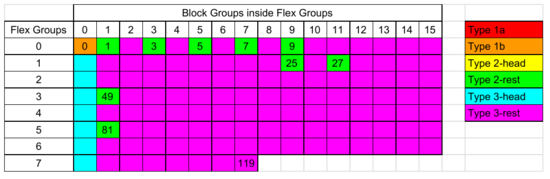
8 Flexible Block Groups, 120 Block Groups and their types
64-bit: You may wonder what happens if the location/index numbers (e.g. the locations in the Group Descriptor) reach to 32-bit maximums. It is not the case with this example, but if you have a large enough storage (probably with number of blocks > 2^32), then ext4 uses the 64-bit mode so important numbers become 64-bit.
Here is also another visual summary:
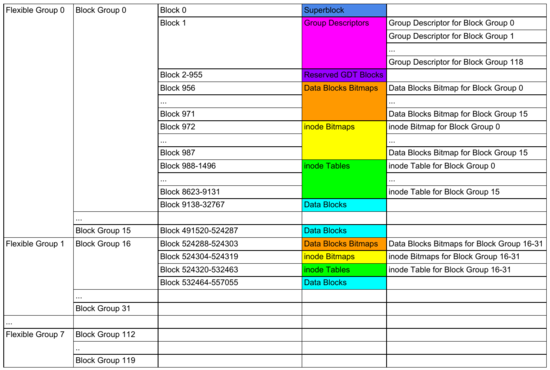
Flexible Groups, Block Groups and Blocks with their contents. Color codes are not same as previous figure.
Looking back now to the unknowns we saw in the output of mkfs, I have described the following:
- Superblock and its backups, sparse_super feature
- Blocks and Block Groups
- flex_bg feature and Flexible Block Groups
- Group Descriptors
- Data Block Bitmap, inode Bitmap and inode Table (but I will show example about them later also)
Now lets talk about inode.
inode
Every file (and directory, and symbolic link, and a few others) in ext4 is associated with an inode, which is basically a structure keeping metadata about the file.
Lets mount the filesystem and create a file and a directory.
$ mkdir usb
$ mount /dev/sda1 usb
$ cd usb
$ echo "test" > testfile
$ mkdir testdir
We can see the inode number of files/directories with:
$ ls -il
total 24
11 drwx------ 2 mete mete 16384 Aug 22 14:36 lost+found
521217 drwxrwxr-x 2 mete mete 4096 Aug 22 15:06 testdir
12 -rw-rw-r-- 1 mete mete 5 Aug 22 15:06 testfile
The -i flag for ls prints the inode numbers on the left.
The lost+found directory is created automatically by mkfs.
In the Superblock, First inode is 11. That is why lost+found is created with inode 11. inode numbers below 11 are reserved, for example Root is at inode 2. We see that with:
$ ls -ila
total 32
2 drwxr-xr-x 4 mete mete 4096 Aug 23 14:56 .
3932162 drwxr-xr-x 104 mete mete 4096 Aug 23 14:59 ..
11 drwx------ 2 mete mete 16384 Aug 23 11:20 lost+found
521217 drwxrwxr-x 2 mete mete 4096 Aug 23 14:56 testdir
12 -rw-rw-r-- 1 mete mete 5 Aug 23 14:56 textfile
Root “.” is at inode 2. Lets look at testdir.
$ ls -ila testdir
total 8
521217 drwxrwxr-x 2 mete mete 4096 Aug 23 14:56 .
2 drwxr-xr-x 4 mete mete 4096 Aug 23 15:05 ..
It is interesting. “.” as we know current directory, is a hard link (why? because it has the same inode number) to directory, and “..” as we know parent directory, is also a hard link to the parent directory. I will explain more later but basically this directory has two entries, one pointing to the inode of the current directory, other pointing to the inode of the parent directory.
Another way to find inode information is with stat utility, which gives more information also by reading the inode and you can run it with the name of the file or directory also.
$ stat testfile
File: 'testfile'
Size: 5 Blocks: 8 IO Block: 4096 regular file
Device: 801h/2049d Inode: 12 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1000/mete) Gid: ( 1000/mete)
Access: 2017-08-22 15:10:27.131878596 +0200
Modify: 2017-08-22 15:06:45.229604104 +0200
Change: 2017-08-22 15:06:45.229604104 +0200
Birth: -
So the testfile is in inode 12. inode keeps information about the type of the file. For testfile, we see it is a regular file.
If you ever need, it is possible to modify the inode structure with debugfs set_inode_field command.
Now, lets see the inode of the current directory which is the root of the filesystem.
$ stat .
File: '.'
Size: 4096 Blocks: 8 IO Block: 4096 directory
Device: 801h/2049d Inode: 2 Links: 4
Access: (0755/drwxr-xr-x) Uid: ( 1000/mete) Gid: ( 1000/mete)
Access: 2017-08-23 14:56:29.067362398 +0200
Modify: 2017-08-23 15:01:07.506634536 +0200
Change: 2017-08-23 15:01:07.506634536 +0200
Birth: -
It is a directory. Other possibilities are:
- symbolic link
- block special file (block device)
- character special file (character device)
- socket
- fifo
You can check all these by stat command. For example:
$ ln -s testfile /tmp/s; stat /tmp/s\
.. symbolic link
$ stat /dev/sda1
... block special file
$ stat /dev/tty
... character special file
$ stat /tmp/.X11-unit/X0
.. socket
$ mkfifo /tmp/f; stat /tmp/f
.. fifo
A better way to see inode structure is with debugfs tool.
$ sudo debugfs -R "stat <2>" /dev/sda1
Inode: 2 Type: directory Mode: 0755 Flags: 0x80000
Generation: 0 Version: 0x00000000:00000007
User: 1000 Group: 1000 Size: 4096
File ACL: 0 Directory ACL: 0
Links: 5 Blockcount: 8
Fragment: Address: 0 Number: 0 Size: 0
ctime: 0x599d7d82:e675788c -- Wed Aug 23 15:05:06 2017
atime: 0x599d7d89:ba90005c -- Wed Aug 23 15:05:13 2017
mtime: 0x599d7d82:e675788c -- Wed Aug 23 15:05:06 2017
crtime: 0x599d48c0:00000000 -- Wed Aug 23 11:20:00 2017
Size of extra inode fields: 32
EXTENTS:
(0):9132
The information in inode 2 is:
- Type: directory. We know it is the file system root.
- Mode: 0775
- Flags: 0x80000 (Inode uses extents, EXT4_EXTENTS_FL bit is set)
- Generation, File Version used for NFS: 0
- Version: 0:8
- User, Owner UID: 1000
- Group, Owner GID: 1000
- Size, in bytes: 4096B. This is actually because it points to a data block and a single data block is 4KB.
- File ACL: 0
- Directory ACL: 0
- Links, Hard Link Count: 5. More about this later.
- Blockcount: 8
- Change (ctime), Access (atime), Modify (mtime), Creation (crtime) Times.
When we execute an ls command, it basically finds the information of the current directory and prints the files/subdirectories it contains. How ?
Directory inode basically points to data blocks containing a structure with directory entries, e.g. files and subdirectories (and other things, symbolic link etc.). A quick way to see this is using debugfs ls command:
$ sudo debugfs -R "ls -l <2>" /dev/sda1
2 40755 (2) 1000 1000 4096 25-Aug-2017 10:51 .
2 40755 (2) 1000 1000 4096 25-Aug-2017 10:51 ..
11 40700 (2) 1000 1000 16384 25-Aug-2017 10:49 lost+found
12 100664 (1) 1000 1000 5 25-Aug-2017 10:51 testfile
521217 40775 (2) 1000 1000 4096 25-Aug-2017 10:51 testdir
We see the inodes (2, 2, 11, 12, 521217) and types (2=dir, 2, 2, 1=file, 2).
Now lets look at the same information in detail. Which blocks are used by the root directory ?
$ sudo debugfs -R "blocks /." /dev/sda1
9132
Block number 9132. We can dump its content with debugfs command block_dump or we can directly use cat to see the contents:
$ sudo debugfs -R "cat <2>" /dev/sda1 | hexdump -C
00000000 02 00 00 00 0c 00 01 02 2e 00 00 00 02 00 00 00 |................|
00000010 0c 00 02 02 2e 2e 00 00 0b 00 00 00 14 00 0a 02 |................|
00000020 6c 6f 73 74 2b 66 6f 75 6e 64 00 00 0c 00 00 00 |lost+found......|
00000030 10 00 08 01 74 65 73 74 66 69 6c 65 01 f4 07 00 |....testfile....|
00000040 c4 0f 07 02 74 65 73 74 64 69 72 00 00 00 00 00 |....testdir.....|
00000050 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00001000
First, as we expect, its size is 4K (last offset is 1000h).
There are two ways a directory may list its entries:
- Linear Directories, this is the default.
- Hash Tree Directories, this is used if EXT4_INDEX_FL flag is set in the diretory inode, which is not set in our case.
There are actually two types of Linear Directory format. Because filetype feature is set for the file system (see the Superblock), ext4_dir_entry_2 type is used. The difference is it contains the type of the file in the directory entry. I believe ext4 always uses this type for linear directories.
Each entry is a variable length record because of the name. Lets take the first entry: (it is in little-endian)
00000000: 0200 0000 0c00 0102 2e00 0000 0200 0000 ................
- inode = 00 00 00 02 = 2
- record length = 00 0c = 12 bytes, including inode and this one, so 6 bytes are already used.
- name length = 01
- file type = 02 (which means directory)
- name = 2e ("." in ASCII)
- padding = 00 00 00
Each entry has to be aligned to 4-byte boundaries, that is the reason for padding.
Similary, for testfile:
00000030: 1000 0702 7465 7374 6469 7200 0c00 0000 ....testdir.....
00000040: c40f 0801 7465 7374 6669 6c65 0000 0000 ....testfile....
- inode = 00 00 00 0c = 12
- record length = 0f c4 = 4036
- name length =08
- file type = 01 (which means regular file)
- name = 74 65 73 74 66 69 6c 65 (“testfile” in ASCII)
- padding = 4036–16 = 4020 bytes of zero.
The last entry consumes all the block, that is why the record length is more than we normally expect.
Out of curiosity, I created many subdirectories in testdir and then it switches to Hash Tree organization (the directory inode flags include EXT4_INDEX_FL). It is possible to dump this information with debugfs htree_dump.
$ sudo debugfs -R "htree_dump /testdir" /dev/sda1
Root node dump:
Reserved zero: 0
Hash Version: 1
Info length: 8
Indirect levels: 0
Flags: 0
Number of entries (count): 373
Number of entries (limit): 508
Entry #0: Hash 0x00000000, block 1
Entry #1: Hash 0x00d9d5e8, block 233
Entry #2: Hash 0x01a2ad40, block 110
... It goes like this to Entry #372, then
Entry #0: Hash 0x00000000, block 1
Reading directory block 1, phys 532805
130455 0x00874f4a-34dc0086 (12) a148
130550 0x002c3106-5e88913e (12) a243
130639 0x00243f50-6401bfe5 (12) a332
130648 0x00590d42-518f46ea (12) a341
... It goes many lines like this for every Entry including #372.
Taking the first line as example:
130455: inode number
12: length of record
a148: name of the folder
Now, lets see the file. Show the contents of data blocks used by inode 12:
$ sudo debugfs -R "cat <12>" /dev/sda1
test
Lets find the contents directly from the disk. The file is at inode 12. Which data blocks does inode 12 use ?
$ sudo debugfs -R "blocks <12>" /dev/sda1
33724
The contents are in file system block 33724. Associated logical blocks start from:
33724 * 4096 / 512 = 269792
We are looking for logical block 269792 :
$ sudo dd if=/dev/sda1 bs=512 skip=269792 count=1 status=none | hexdump -C
00000000 74 65 73 74 0a 00 00 00 00 00 00 00 00 00 00 00 |test............|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00000200
We found it.
How does debugfs blocks command works ? The data blocks used by an inode is kept in the i_block element of the inode structure. It is 60 bytes.
There are four possibilities:
- For Symbolic Links, if the name of the target fits to 60 bytes, it is stored here. If not, other methods below are used.
- If Inline Data feature is enabled, and if the contents of a file is less than 60 bytes, it can be directly stored, not our case.
- In Direct/Indirect Block Addressing, there are 11 direct, 1 indirect, 1 double indirect, 1 triple indirect (total 15, since 60 bytes / 4 = 15) maps. Indirect means the block at that address is not a data block but another block listing addresses of another address blocks, and it is possible to have one 1, one 2 (double), one 3 (triple) indirections. So with 4K blocks, it is possible to address
11 + 1024 + 1024*1024 + 1024*1024*1024blocks. However, no address can be 64-bits (since each address is 4 bytes). My understanding is Direct/Indirect Block Addressing was used in ext2 and ext3, but not in ext4 anymore. - Extent Tree is used in ext4 and inode has a flag for it (EXT4_EXTENTS_FL, see above). Extent Tree is a tree with a maximum depth 5 and with a maximum branching factor of 2¹⁶ = 64K. It is more efficient than Direct/Indirect Block Addressing, and can address 64-bit block addresses.
Extent Tree is used because of the filesystem feature extent is enabled, see Superblock.
It is not very easy to follow raw Extent Tree structure since it is a tree, but we can dump it with the help of debugfs.
$ sudo debugfs -R "dump_extents <12>" /dev/sda1
Level Entries Logical Physical Length Flags
0/ 0 1/ 1 0 - 0 33724 - 33724 1
As expected, there is only 1 entry.
Lets create a large file and then look at its Extent Tree. I am using fallocate here which only allocates the data blocks but do not write anything on them. If you use dd if=/dev/zero it takes a long time to write zeroes to all data blocks.
$ fallocate -l 10GB largefile
$ ls -ila largefile
13 -rw-rw-r-- 1 mete mete 10737418240 Aug 25 09:03 largefile
$ sudo debugfs -R "dump_extents <13>" /dev/sda1
Level Entries Logical Physical Length Flags
0/ 1 1/ 1 0 - 2621439 33724 2621440
1/ 1 1/ 92 0 - 30719 34816 - 65535 30720 Uninit
1/ 1 2/ 92 30720 - 61439 65536 - 96255 30720 Uninit
...
...
...
1/ 1 92/ 92 2592768 - 2621439 2840576 - 2869247 28672 Uninit
Now we have a tree of depth=2 (level 0 and level 1). Level 0 is the indirect addressing page, then there are 92 pages with addresses of blocks. As I mentioned above, we have only allocated space, the blocks are uninitialized (Uninit flag). Also, note that 10GB file is addressed with only 2 levels, there can be up to 5 levels.
Revisiting Links
For the symbolic link, I said the name of the target is kept at data blocks. This is the main difference between a hard link and a symbolic link. Hard link is a direct pointer to an inode — just a different name in directory entries — , whereas Symbolic link is an indirect pointer through the name of the file / directory.
Lets make an example:
$ touch t
$ ln t hl
$ ln -s t sl
$ ls -ila
13 -rw-rw-r — 2 mete mete 0 Aug 25 12:18 hl
14 lrwxrwxrwx 1 mete mete 1 Aug 25 12:18 sl -> t
13 -rw-rw-r — 2 mete mete 0 Aug 25 12:18 t
As you see, actual file is at inode 13. Symbolic link is at a new inode 14. However, hard link is pointing to same inode 13. So it is just a directory entry, it does not have its own inode or data blocks. If you check debugfs stat /t and /hl output, they are same.
This is the reason you cannot have an hard link pointing something that does not exists, whereas it is possible to do this with a symbolic link, since it is just a name/path, it can be anything. Hard link has to point an existing inode.
What happens if I delete the file or hard link ? Nothing, because there is still another name pointing to the inode. The # of links number in inode is updated accordingly, so until there is no hard link left, the inode is not deleted.
Another way of thinking about these are:
- File is an inode, at least one hard link and data.
- Directory is an inode, at least two hard links (one from itself, one from parent), and its directory entries data.
- Symbolic link is an inode, at least one hard link and a path.
Mind bending, but yes, you can have a hard link for a symbolic link pointing to a hard link for file.
Other File System Features
For the sake of completeness, I would like to tell you about:
- dir_index: Basically it enables the use of Hash Tree Directory entries. However, the corresponding inode of directory should also have the flag EXT4_INDEX_FL set if it is in use.
- dir_nlink: Normally the number of hardlinks to an inode is kept in the inode structure, as an 16-bit number. That means there can be maximum 64K hard links to an inode. On the other hand, since all subdirectories of a directory contain the entry “..” for the parent directory as a hard link, it means there can be only 64K subdirectories of a directory. When dir_nlinks feature is present, ext4 does not keep track of this counter for directories, if more than 64K subdirectories is used, when it is the case, it is set to 1.
Actually a directory can have a maximum 64K - 2 subdirectories. Since there is always a reference to it from the parent directory, and there is a reference to itself.
I have tested this with a simple bash script and executed this in testdir:
for N in {1..65000}
do
mkdir a$N
done
Just before it was finished:
$ stat testdir
File: 'testdir'
Size: 1519616 Blocks: 2976 IO Block: 4096 directory
Device: 801h/2049d Inode: 130305 Links: 64814
Access: (0775/drwxrwxr-x) Uid: ( 1000/ mete) Gid: ( 1000/ mete)
Access: 2017-08-25 14:44:49.801116026 +0200
Modify: 2017-08-25 14:45:41.700236949 +0200
Change: 2017-08-25 14:45:41.700236949 +0200
After it has finished:
$ stat testdir
File: 'testdir'
Size: 1531904 Blocks: 3000 IO Block: 4096 directory
Device: 801h/2049d Inode: 130305 Links: 1
Access: (0775/drwxrwxr-x) Uid: ( 1000/ mete) Gid: ( 1000/ mete)
Access: 2017-08-25 14:44:49.801116026 +0200
Modify: 2017-08-25 14:45:41.992232003 +0200
Change: 2017-08-25 14:45:41.992232003 +0200
In case you wonder, deleting subdirectories does not return back the real hard link counting. It stays at 1.
Also, it seems there is an optimization and after creating so many subdirectories, testdir has switched to Hash Tree mode.
- huge_file: If huge_file is not set, the maximum size a file can have is 2³² Logical Blocks. If it is set, but EXT4_HUGE_FILE_FL is not set on the inode, that it is possible to have file size of 2⁴⁸ Logical Blocks (very large number). If also EXT4_HUGE_FILE_FL is set, then maximum file size is 2⁴⁸ File System Blocks. 2⁴⁸ Logical Blocks is already a very large number and I think it is not possible because maximum Extent Tree is smaller, so I am not sure why there is a possibility of such a flag on inode.
Bitmaps
We know testfile is at inode 12 and its data block is at Block 33724.
Lets first look at Data Block Bitmap for Block 33724. It is in Block Group 1 (since each Block Group contains 32768 Blocks), so we should look at the Data Block Bitmap of Block Group 1, which stays in Block Group 0, Block 957. Also, it is the Block 33724–32768=956 in Block Group 1, so we should look at Bit 956 in the Data Block Bitmap, which should be in Byte offset 956 / 8 = 119 = 0x77 at Bit 4.
Dump Block 957, skip 119 bytes and take 1 byte, show bits
$ dd if=/dev/sda1 bs=4096 skip=957 count=1 status=none | xxd -s 119 -l 1 -b
00000077: 00011111
Bit 4 is set, so it is in use.
To double check, we can use debugfs to dump who uses this block, and also lets see the next and the previous one:
$ sudo debugfs -R "icheck 33725 33724 33723" /dev/sda1
Block Inode number
33725 <block not found>
33724 12
33723 7
It confirms what we saw in the Data Block Bitmap, next block is empty (Bit 5 = 0), previous block is used (Bit 3 = 1) by a different inode.
Now, lets check the inode Bitmap. inode 12 is used but inode 13 should be free. Since each Block Group has 8144 inodes (see Inodes per group in Superblock), this should be in the inode Bitmap of Block Group 0, which starts at Block 972.
Dump block 972, take 4 bytes, show bits
$ sudo dd if=/dev/sda1 bs=4096 skip=972 count=1 status=none | xxd -s 0 -l 2 -b
00000000: 11111111 00001111
Bit 11 is set. The inode numbers start from 1, that is why I am looking at Bit 11 not Bit 12. As Bit 11 is set, inode 12 is in use.
We see above inode 13 should be free. Lets confirm that with debugfs.
$ sudo debugfs -R "inode_dump <13>" /dev/sda1
0000 0000 0000 0000 0000 0000 0000 0000 0000 ................
*
As we already found out, inode 13 is free.
Now, lets talk about the Journal.
Journal
For normal functioning of the file system, Journal is not needed. However, for performance reasons, we do not want to write or sync every change to ext4. If the system crashes meanwhile, the changes that are not written to ext4 will be lost. That is where Journal is needed. Every such operation is written to Journal first (not to ext4 first) and it is finalized later (written to ext4 later). If the system crashes, during recovery, probably on the next boot, Journal is replied back to ext4 so changes are applied and not lost.
Journal can be used in three different modes. This can be set with the mount option data.
- journal: All data (both metadata and actual data) is written to Journal first, so the safest.
- ordered: This is the default mode. All data is sent to ext4, metadata is sent to Journal also. No protection for data but metadata is protected for crash.
- writeback: Data can be written to ext4 before or after being written to Journal. On a crash, new data may get lost.
The information / blocks is written to Journal like this:
- First, a Descriptor Block is written, containing the information about the final locations of this operation.
- Second, a Data Block is written. It can be actual data or meta data.
- Third, a Commit Block is written. After this, the data can be sent to ext4.
Other than Commit Block, ongoing operation can be cancelled with a Revocation Block. Also, if a Commit Block is not found, when a replay happens (e.g. crash then recovery), it is not written to ext4.
Another device can be used as a Journal, but usually Journal is a file inside ext4. Looking back to Superblock, we can see:
- has_journal feature is set, so we are using a Journal.
- Journal inode is 8
- Journal size is 128M
- Journal length is 32K (of Journal blocks)
The Journal is kept in ext4, but, I think, because inode 8 is not listed in any directory entries, it is hidden. Lets look at its inode:
$ sudo debugfs -R "stat <8>" /dev/sda1
Inode: 8 Type: regular Mode: 0600 Flags: 0x80000
Generation: 0 Version: 0x00000000:00000000
User: 0 Group: 0 Size: 134217728
File ACL: 0 Directory ACL: 0
Links: 1 Blockcount: 262144
Fragment: Address: 0 Number: 0 Size: 0
ctime: 0x599fcb62:00000000 -- Fri Aug 25 09:01:54 2017
atime: 0x599fcb62:00000000 -- Fri Aug 25 09:01:54 2017
mtime: 0x599fcb62:00000000 -- Fri Aug 25 09:01:54 2017
crtime: 0x599fcb62:00000000 -- Fri Aug 25 09:01:54 2017
Size of extra inode fields: 28
EXTENTS:
(0-32766):1606588-1639354, (32767):1639355
It is a file with mode 0600 meaning it can only be read and written by the owner (which is root, UID=0). Maybe a solution to make Journal visible would be to change the entries of a directory and add inode <8>. To do this, I dumped the inode data of testdir, and manually modified (using hexeditor called bless) it to include inode <8> with name J .
The current directory entries are:
$ sudo debugfs -R "cat /testdir" /dev/sda1 | hexdump -C
00000000 01 f4 07 00 0c 00 01 02 2e 00 00 00 02 00 00 00 |................|
00000010 f4 0f 02 02 2e 2e 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00001000
I have added a new 3rd entry and modified the size of 2nd:
$ hexdump -C ../testdir.block
00000000 01 f4 07 00 0c 00 01 02 2e 00 00 00 02 00 00 00 |................|
00000010 0c 00 02 02 2e 2e 00 00 08 00 00 00 e8 0f 01 01 |................|
00000020 4a 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |J...............|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00000400
Which block do we need to write onto ?
$ sudo debugfs -R "blocks /testdir" /dev/sda1
2105328
Now write it back:
Warning ! Be very careful doing this, make sure the device you provide has no data you care about.
Lets make a backup before:
$ sudo dd if=/dev/sda1 bs=4096 skip=2105328 count=1 status=none of=../testdir.backup
Now write the modified data:
$ sudo dd if=../testdir.block ibs=1024 count=1 of=/dev/sda1 obs=4096 seek=2105328
Lets see the entries:
$ sudo debugfs -R "ls -l <521217>" /dev/sda1
521217 40775 (2) 1000 1000 4096 25-Aug-2017 10:51 .
2 40755 (2) 1000 1000 4096 25-Aug-2017 10:51 ..
8 100600 (1) 0 0 134217728 25-Aug-2017 10:49 J
It looks OK. However, if I try to ls, I get an error. I am not sure why, if I am doing something wrong or it is because Journal is special. Let me know if you know the answer.
$ ls -ila testdir
ls: cannot access 'testdir/J': Structure needs cleaning
total 8
521217 drwxrwxr-x 2 mete mete 4096 Aug 25 10:51 .
2 drwxr-xr-x 4 mete mete 4096 Aug 25 10:51 ..
? -????????? ? ? ? ? ? J
Conclusion
I have covered the following ext4 topics in this article.
- Superblock
- Basic layout of ext4, Blocks and Block Groups
- sparse_super and flex_bg and other basic file system features
- Flexible Block Groups
- Data Blocks Bitmap
- inode Blocks Bitmap and inode Table
- inode
- Directory entries
- Hard and Symbolic Links
- Journal
I did not cover:
- Details of meta_bg
- Details of (Un)Initialization of Blocks and inodes
- Various Checksums
- Various compatibility and incompatibility flags
- Details of 64-bit file system
- Preallocation of blocks
- Details of inode, especially modes, ACL, flags
- Details of Hash Tree format of directory entries
- Extended attributes
I hope this post helps you to understand how ext4 works.
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.